
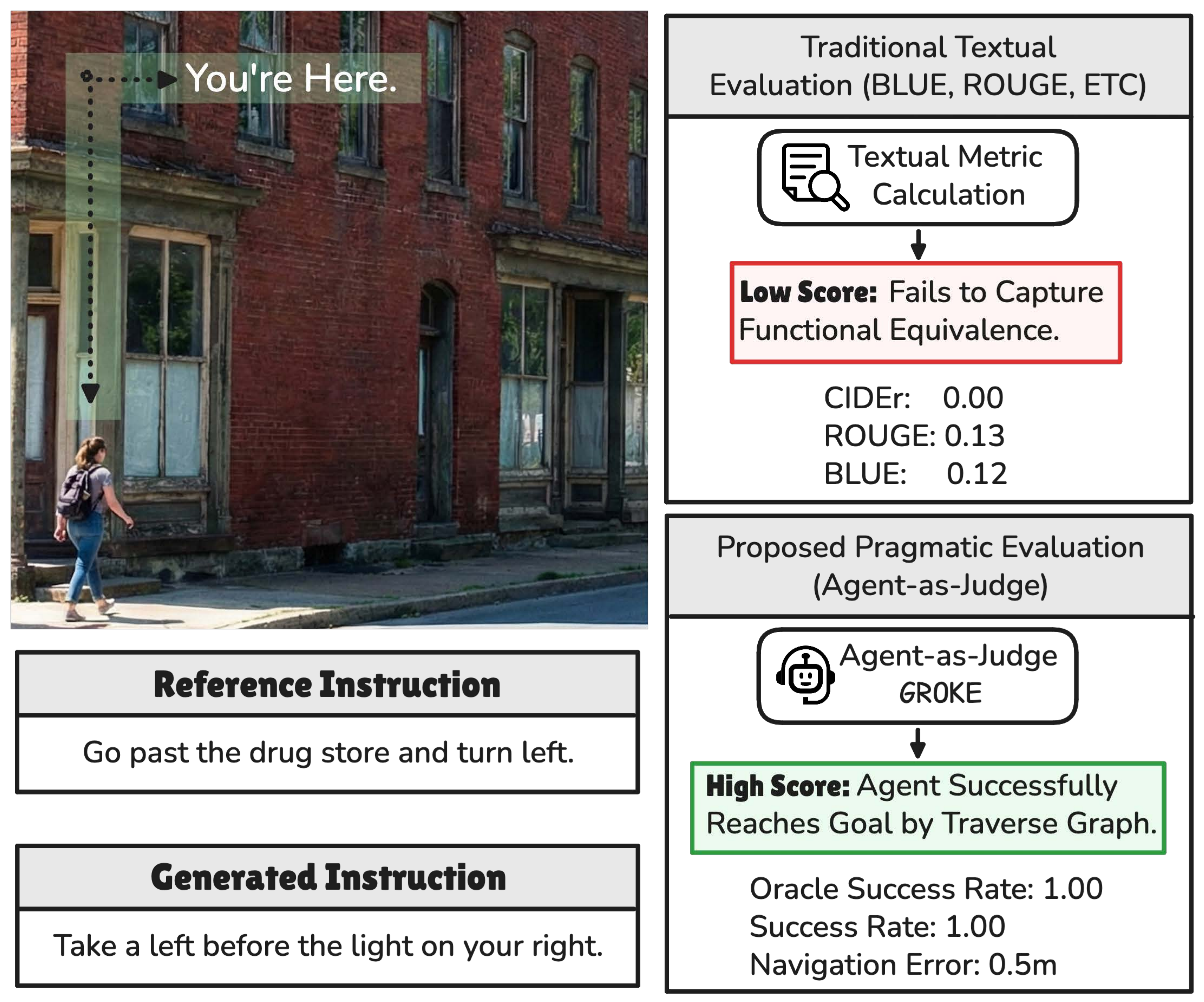
Most evaluation pipelines for navigation instructions still rely on reference-based text metrics borrowed from machine translation and captioning — BLEU, ROUGE, METEOR, CIDEr. These metrics assume that there is a single correct way to describe a route and that lexical similarity correlates with functional utility. In navigation, this assumption breaks down: "Turn left at the bank" and "Turn right at the bank" share almost all of their tokens yet describe opposite trajectories, while "Go past the drug store and turn left" and "Take a left before the light on your right" can share zero n-grams while describing the same valid action.
Pragmatic alternatives evaluate instructions by sending a follower agent through a high-fidelity visual simulator (Matterport3D, Google Street View) and measuring its success rate. This conflates linguistic quality with visual recognition, hits the licensing and bandwidth ceiling of proprietary panoramas, and limits reproducibility to well-funded labs.
GROKE inverts the standard VLN question. Instead of asking "how well did the agent perform?", we ask "how navigable is this instruction?" — and treat agent execution metrics (Navigation Error, Success Rate, SDTW) as proxy scores for the input text. By replacing pixels with OpenStreetMap graphs (nodes, edges, POIs), GROKE removes the visual recognition bottleneck and enables scalable, vision-free assessment of instruction quality.
We formulate VLN over OpenStreetMap as sequential decision-making on a graph \(\mathcal{G} = (V, E, P)\), where \(V\) is the set of navigable nodes, \(E\) the directed edges with associated headings, and \(P\) the points of interest with semantic tags. Given an instruction \(I\), the goal is a policy \(\pi: (I, v_t, h_t, \mathcal{G}_t) \rightarrow v_{t+1}\) that selects the next waypoint from the local map context.
GROKE is a training-free, multi-agent hierarchical system composed of three modules:
MOVE_FORWARD, TURN_LEFT, TURN_RIGHT) and extracts landmark mentions, which are grounded onto OSM POIs via fuzzy string matching (RapidFuzz).IN_PROGRESS, COMPLETED).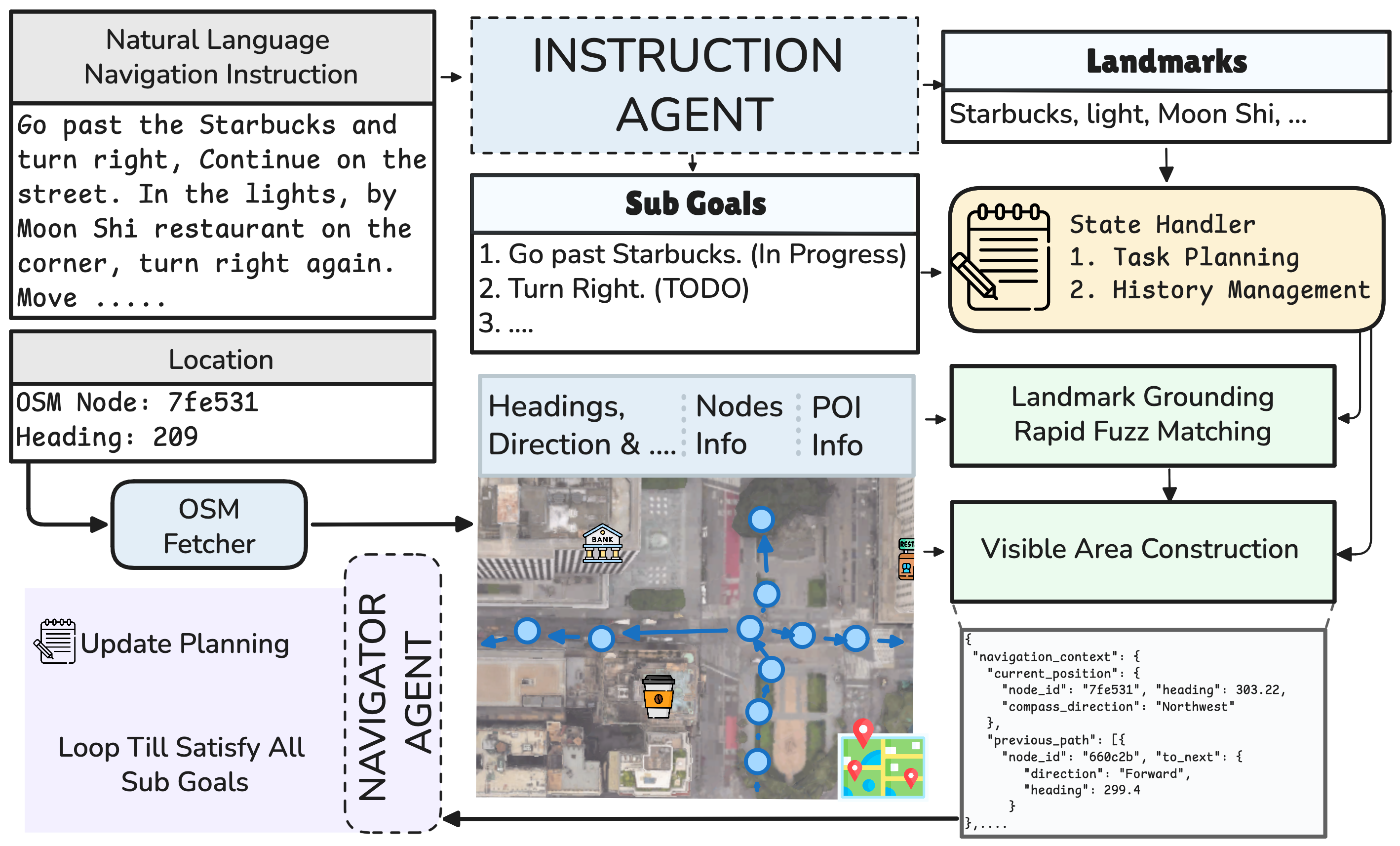
We evaluate GROKE on two 700-instance test splits of Map2Seq (TestA and TestB, corresponding to the Test_Seen and Test_Unseen splits of the original release). Following standard VLN protocols we report Navigation Error (NE), Success Rate (SR), Oracle Success Rate (OSR), and Success weighted by Dynamic Time Warping (SDTW). The Navigator Agent runs on Gemini-3 Pro with the default thinking configuration.
| Method | TestA | TestB | ||||||
|---|---|---|---|---|---|---|---|---|
| NE ↓ | SR ↑ | OSR ↑ | SDTW ↑ | NE ↓ | SR ↑ | OSR ↑ | SDTW ↑ | |
| Random Walker | 259.0 | 4.4% | 5.7% | 0.026 | 244.3 | 6.1% | 7.1% | 0.029 |
| Action Sampling | 250.1 | 5.1% | 6.0% | 0.037 | 241.6 | 7.4% | 8.1% | 0.039 |
| Heuristic Agent | 180.6 | 18.0% | 18.9% | 0.155 | 173.0 | 17.9% | 19.1% | 0.159 |
| GROKE (Ours) | 56.8 | 66.4% | 78.4% | 0.634 | 59.8 | 63.3% | 78.0% | 0.609 |
Table 1: Overall navigation execution results. The best baseline per column is underlined.
GROKE reduces Navigation Error by roughly 68.5% compared with the strongest baseline (Heuristic Agent) and lifts Success Rate from 18.0% to 66.4% on TestA. The gains transfer to the unseen split (TestB: SR 17.9% → 63.3%), confirming that semantic graph reasoning generalises beyond the training distribution.
On 100 randomly sampled instructions rated by human annotators, Navigation Error shows the strongest agreement with human ratings (Pearson r = −0.31, p < 0.01; Spearman ρ = −0.32, p < 0.01). SR, SDTW, and nDTW are also significantly correlated; OSR alone fails to reach significance. These results support using NE and nDTW as primary proxies when human-in-the-loop validation is infeasible.
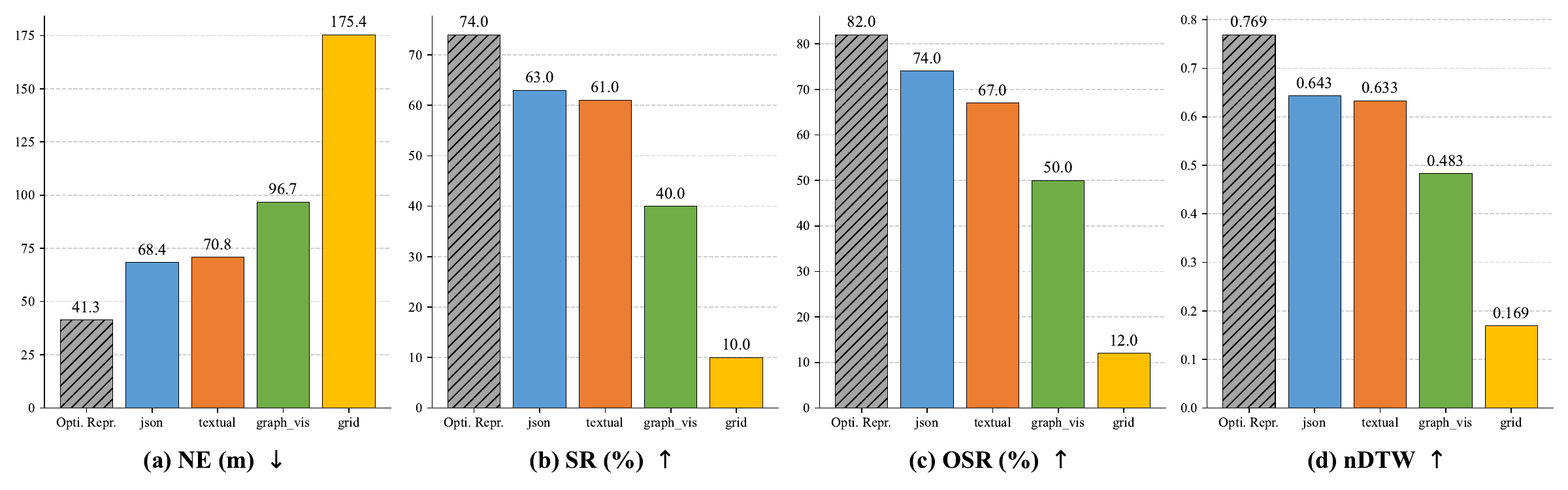
We compare four ways of feeding the visible area to the LLM: a Textual narrative, a Structured JSON graph, Graphviz-style notation, and a Grid (matrix) rendering. Structured JSON and Textual encodings clearly outperform the visual-style formats; the Grid representation collapses to near-baseline performance (NE 175.4 m, SR 10%). On hard instructions JSON pulls further ahead of Textual, suggesting that hierarchical structure helps the LLM recover from compounding errors.
We compare three instruction-feeding strategies: complete instruction, rule-based sentence split, and our LLM Divider that produces semantically grounded atomic sub-goals. The LLM Divider reduces NE by 42.6% relative to the complete-instruction baseline (41.3 m vs. 71.9 m) and raises SR from 51.0% to 74.0%. The advantage is largest on hard instructions, where SR jumps from 23.1% to 53.8%.
| Method | NE ↓ | SR ↑ | OSR ↑ | nDTW ↑ |
|---|---|---|---|---|
| Complete Instruction | 71.9 | 51.0% | 55.0% | 0.496 |
| Rule-based Split | 58.4 | 54.0% | 69.0% | 0.509 |
| LLM Divider (Ours) | 41.3 | 74.0% | 82.0% | 0.714 |
Table 2: Impact of sub-instruction decomposition (100 validation instances).
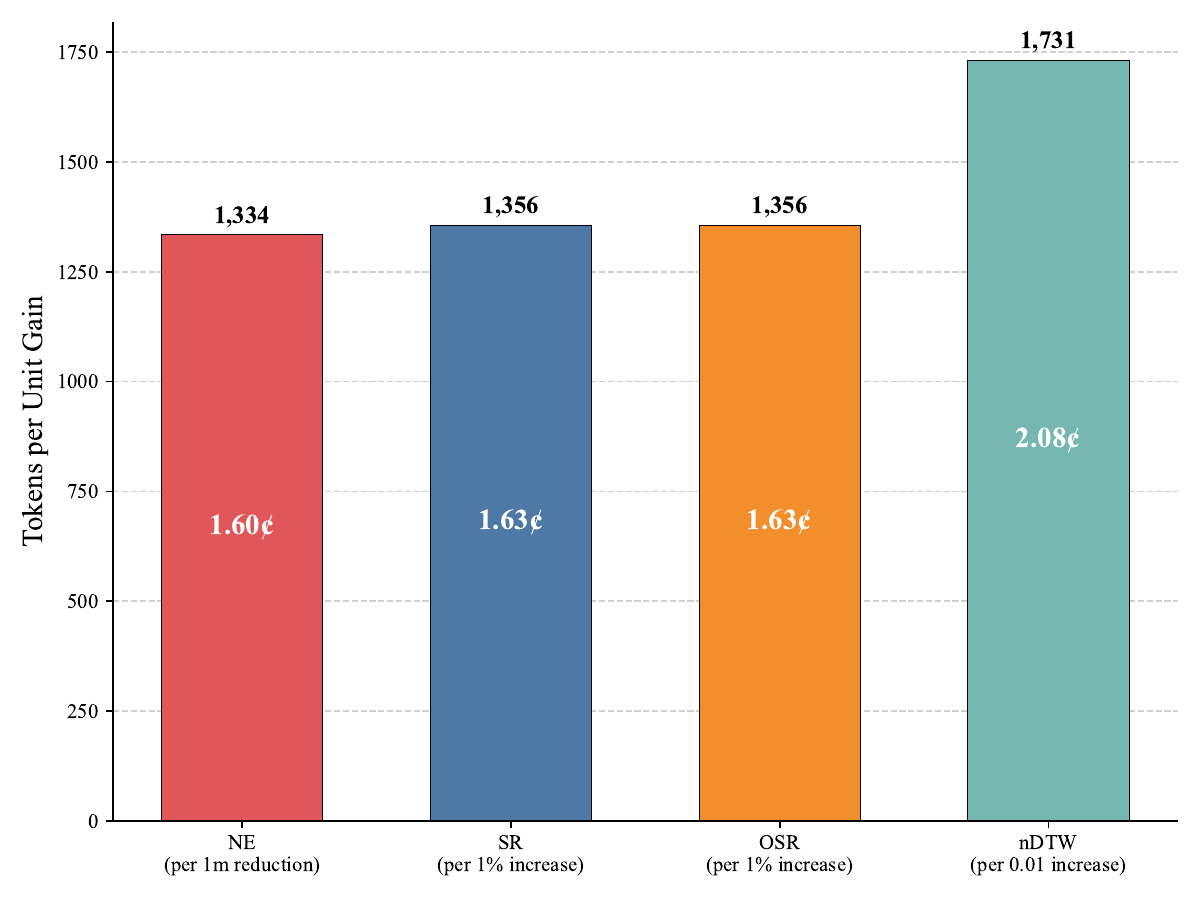
Higher thinking budgets help on hard instructions but follow a clear law of diminishing returns. The Low setting consumes ~33k tokens on average, High ~41k, and Auto ~44k. Each additional metre of NE reduction costs roughly 1,334 thought tokens (~1.6¢ at $12 / M tokens), and a 0.01 increase in nDTW costs ~1,731 tokens.
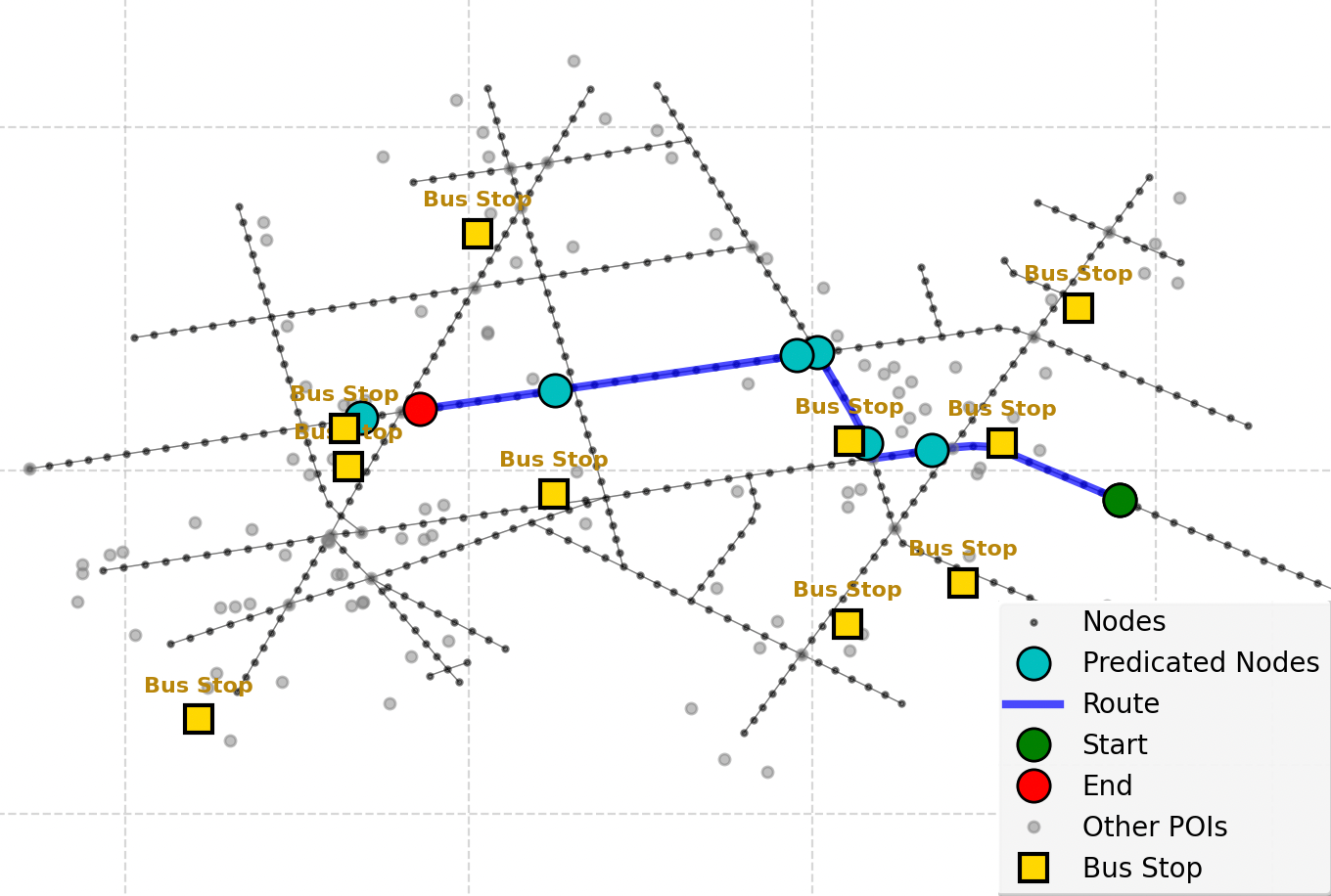
A common failure pattern is overshooting the goal: when a landmark (e.g. a bus stop) is mentioned as a stopping reference, the agent occasionally treats it as a navigation destination and walks past the intended stopping intersection.
@inproceedings{shami-etal-2026-groke,
title = "{GROKE}: Vision-Free Navigation Instruction Evaluation via Graph Reasoning on {O}pen{S}treet{M}ap",
author = "Shami, Farzad and
Dey, Subhrasankha and
de Weghe, Nico Van and
Tenkanen, Henrikki",
editor = "Liakata, Maria and
Moreira, Viviane P. and
Zhang, Jiajun and
Jurgens, David",
booktitle = "Proceedings of the 64th Annual Meeting of the {A}ssociation for {C}omputational {L}inguistics (Volume 1: Long Papers)",
month = jul,
year = "2026",
address = "San Diego, California, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2026.acl-long.1874/",
doi = "10.18653/v1/2026.acl-long.1874",
pages = "40371--40391",
ISBN = "979-8-89176-390-6",
abstract = "The evaluation of navigation instructions remains a persistent challenge in Vision-and-Language Navigation (VLN) research. Traditional reference-based metrics such as BLEU and ROUGE fail to capture the functional utility of spatial directives, specifically whether an instruction successfully guides a navigator to the intended destination. Although existing VLN agents could serve as evaluators, their reliance on high-fidelity visual simulators introduces licensing constraints and computational costs, and perception errors further confound linguistic quality assessment. This paper introduces GROKE (Graph-based Reasoning over OSM Knowledge for instruction Evaluation), a vision-free training-free hierarchical LLM-based framework for evaluating navigation instructions using OpenStreetMap data. Through systematic ablation studies, we demonstrate that structured JSON and textual formats for spatial information substantially outperform grid-based and visual graph representations. Our hierarchical architecture combines sub-instruction planning with topological graph navigation, reducing navigation error by 68.5{\%} compared to heuristic and sampling baselines on the Map2Seq dataset. The agent{'}s execution success, trajectory fidelity, and decision patterns serve as proxy metrics for functional navigability given OSM-visible landmarks and topology, establishing a scalable and interpretable evaluation paradigm without visual dependencies."
}